無
課程重要公告
(一)本課程為 實體課程 與 線上直播課程 同步進行,擇一參加即可,亦可依自身狀況,時而參加實體課程,時而進行線上課程。
(二)實體課程授課地點於東吳大學城中校區。
(三)線上直播課程的部分,預計以 Google Meet 實施遠距授課為主,確定開課後亦將提供Google Meet操作協助。
(四)因應課程需求,【電腦環境】採用Anaconda以及Jupyter notebook開發環境,學員需於課前事先自行安裝,以利課程進行。
課程內容(一堂課程約3小時/ 4節課)
大數據時代,網路世界遍佈著各式各樣的寶貴資料,網路爬蟲(Web Crawler),也被稱為網路蜘蛛(Spider);此技術儼然成為自動下載不可或缺的基本技能之一。
本課程非常重視學習的正確路徑,所以會從最基本的各種數據資料技術開始,讓學習者先瞭解HTML(HyperText Markup Language,超文本標記語言)、XML(Extensible Markup Language,可延伸標記式語言)以及JSON(JavaScript Object Notation,JavaScript物件表示法)的相關技術。透過HTTP(HyperText Transfer Protocol,超文本傳輸協定)的基本運作,了解網路連線的幾種模式,然後使用非常強大的Python模組BeautifulSoup進行剖析,再利用XPath (XML Path Language,XML路徑語言)與CSS Selector的節點定位,讓每位學員皆可在實戰中輕易地將網路資料爬取下來。
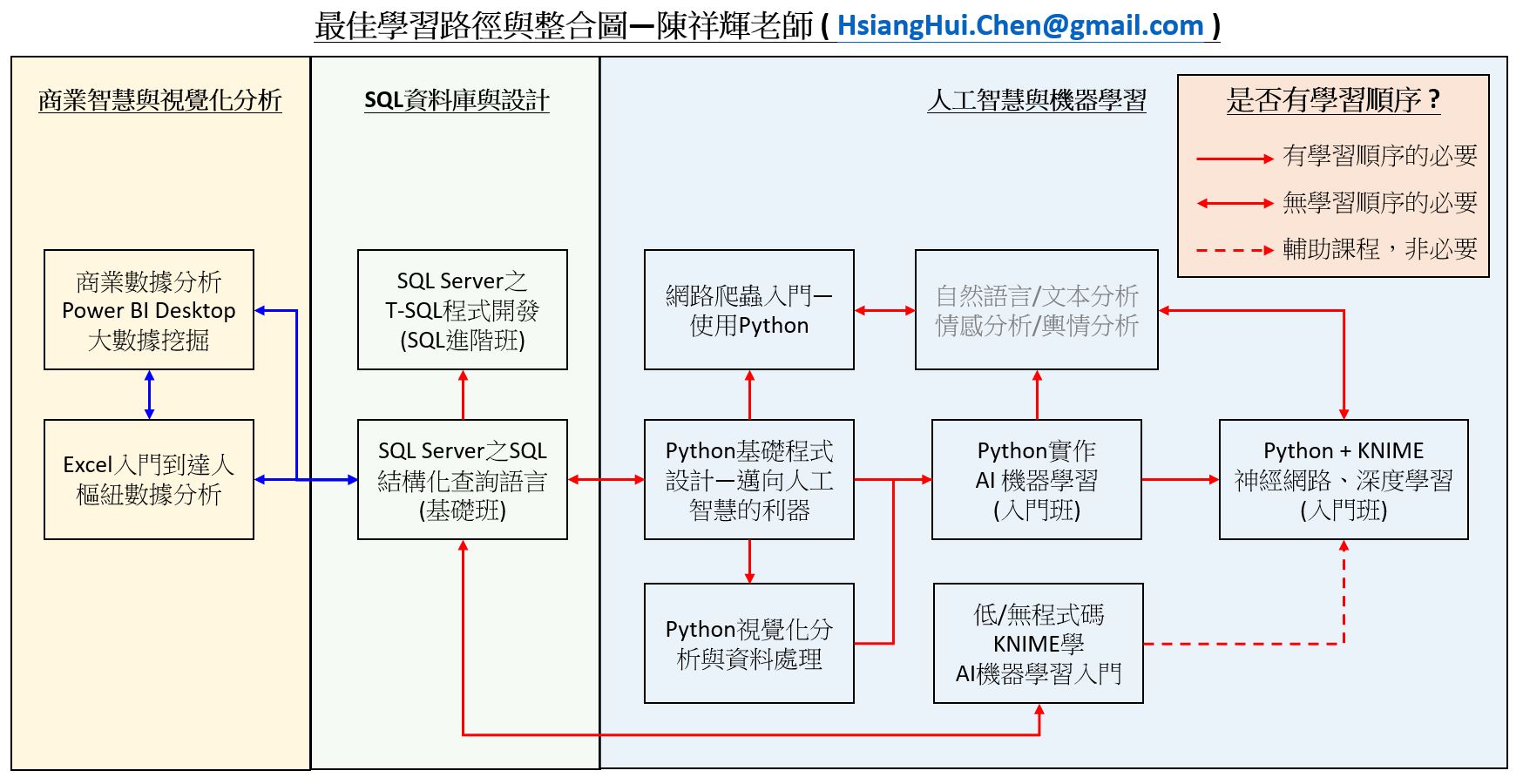
● 本課程必須事先具備Python基本程式設計基礎,透過本課程觀念的建立後,以及不斷的實戰演練,期許每位學員都可以從最基本的網路新聞、填寫表單、Cookies、防止機器人、利用Selenium來操控各式瀏覽器來進行爬蟲的動作。
● 務必具備『Python』基礎的撰寫能力與Jupyter Notebook的開發環境使用,否則建議先上『Python基礎程式設計--邁向人工智慧的利器』
| 週次 | 課程內容 |
| 第一堂 | 基礎環境與數據資料技術簡介 |
| 第二堂 | 認識XPath、CSS Selector選取器,並且上網實戰爬取各家新聞資料 |
| 第三堂 | 認識GET/POST以及各種不同的技巧、換頁和直接取得JSON資料 |
| 第四堂 | Selenium的各種模式介紹與實戰 |
上過陳祥輝老師課的學員都說!讚!!